What Is AI Hallucination (Fabrication)?
LLMs can hallucinate—but in some cases they also regurgitate memorized text. This post clarifies the difference and outlines RAG/GraphRAG plus test-time compute techniques to reduce risk in enterprise systems.
Artificial intelligence—especially Large Language Models (LLMs)—rests on a strange paradox: in front of us stands a system that looks like it has “read” all the world’s knowledge, yet the same system can sometimes invent even the simplest fact and present it with great confidence. In the literature, this is called “hallucination.” Most of the time it doesn’t happen because the system is “broken,” but because of the model’s nature: LLMs are not “reality engines”; they are probabilistic language engines.
Prediction or memory? The reality of “regurgitation” (reproduction)
A common misconception is that LLMs store information on shelves like a library. Technically, LLMs are not databases; they predict the next token (often not a full word, but a word piece) in the most likely way. This is also what the foundational work behind the Transformer architecture is about: producing the “most likely continuation” from patterns in language. (Vaswani et al., 2017)
But there is a critical exception: regurgitation. Normally, we expect models to generalize and produce “new” sentences. Yet under certain conditions (e.g., heavy repetition in the training data, overfitting, training dynamics that unintentionally encourage memorization), a model can reproduce a text it has seen before with high similarity. This risk frequently comes up in copyright debates and lawsuits: for example, in The New York Times’ case against OpenAI/Microsoft, claims around “reproduction of content in outputs” have been part of the discussion. In the Getty–Stability AI line, the issue is not only “copying,” but also includes multiple dimensions such as how training data was obtained and trademark/watermark concerns.
Reining in hallucinations: not “talk,” but “prove”

The most effective way to reduce hallucinations is to tie the model to evidence rather than forcing it to speak from “memory.” In practice, three approaches stand out:
-
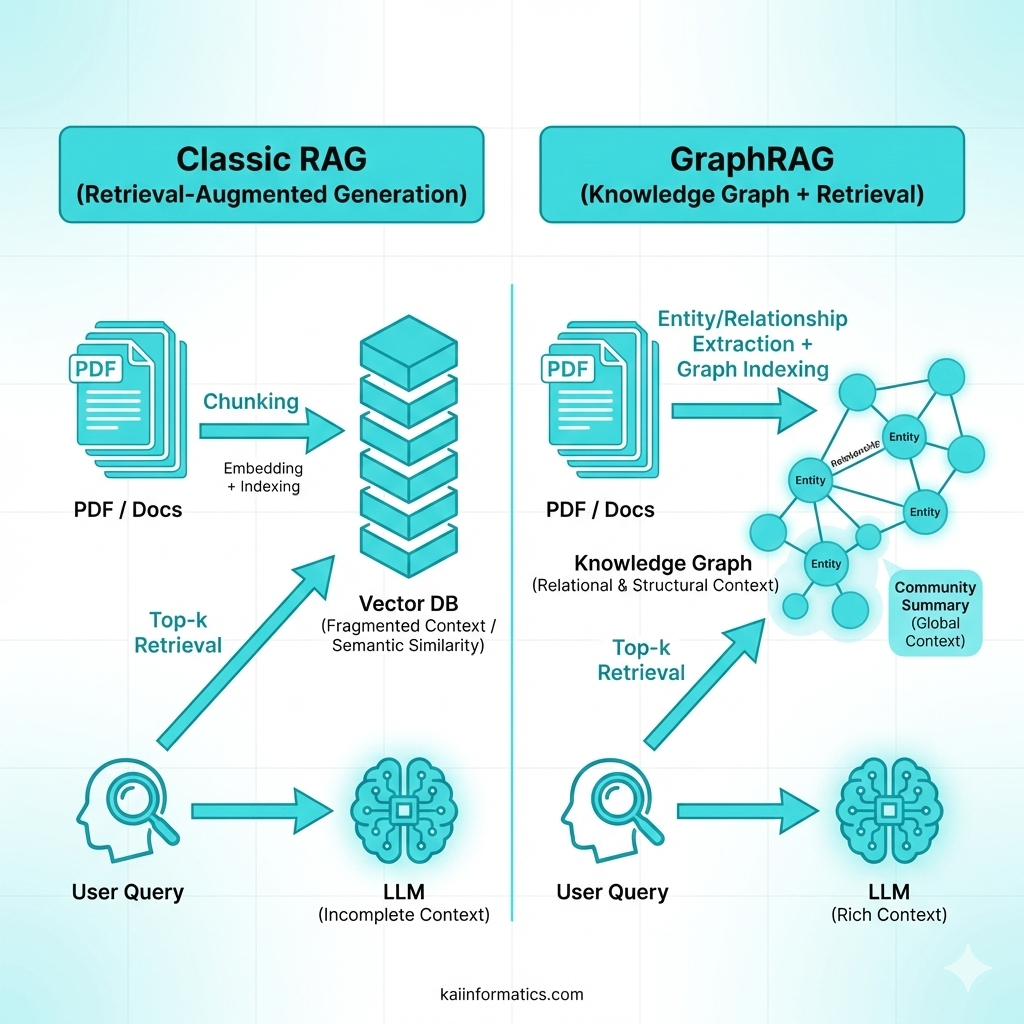
Classic RAG (Retrieval-Augmented Generation)
RAG connects the model to an information source (e.g., a vector database) and retrieves relevant documents before generating an answer (Lewis et al., 2020). The model “produces language,” but the content “rests on documents.”
- Pros: Provides grounding and reduces hallucinations.
- Cons: Chunk-based reading can miss complex relationships.
-
Chain-of-Thought and variants (step-by-step reasoning)
Chain-of-Thought (Wei et al., 2022) enables the model to produce intermediate steps instead of answering in a single shot. This can increase the chance of catching errors—but by itself, it is not a guarantee. (Techniques like self-consistency and reflection also come into play here.)
-
GraphRAG + Test-Time Compute (inference-time scaling)
GraphRAG aims to index documents not only as fragments, but as a graph built from entities and relationships (knowledge graph / community summary), and to answer queries using that structure (Edge et al., 2024). Test-time compute aims to improve correctness by giving the model more “thinking budget” at inference time (e.g., trying multiple solution paths, selecting among them, reasoning longer); OpenAI explicitly emphasizes that o1’s performance improves with test-time compute.
Technical terms
- Token: The unit the model processes; often a word piece (subword).
- Overfitting: When the model “memorizes” training data and performs worse on new situations.
- Vector database: Data infrastructure that performs embedding-based semantic search.
- Inference: The process of an AI model producing outputs for new inputs after training.
- Ontology / Knowledge graph: A formal representation of concepts and their relationships.
Conclusion
Because LLMs are “prediction machines,” the risk of hallucination never fully disappears. But when evidence-grounded generation (RAG/GraphRAG) is combined with an inference-time “thinking budget” (test-time compute), the reliability threshold for enterprise use rises significantly.
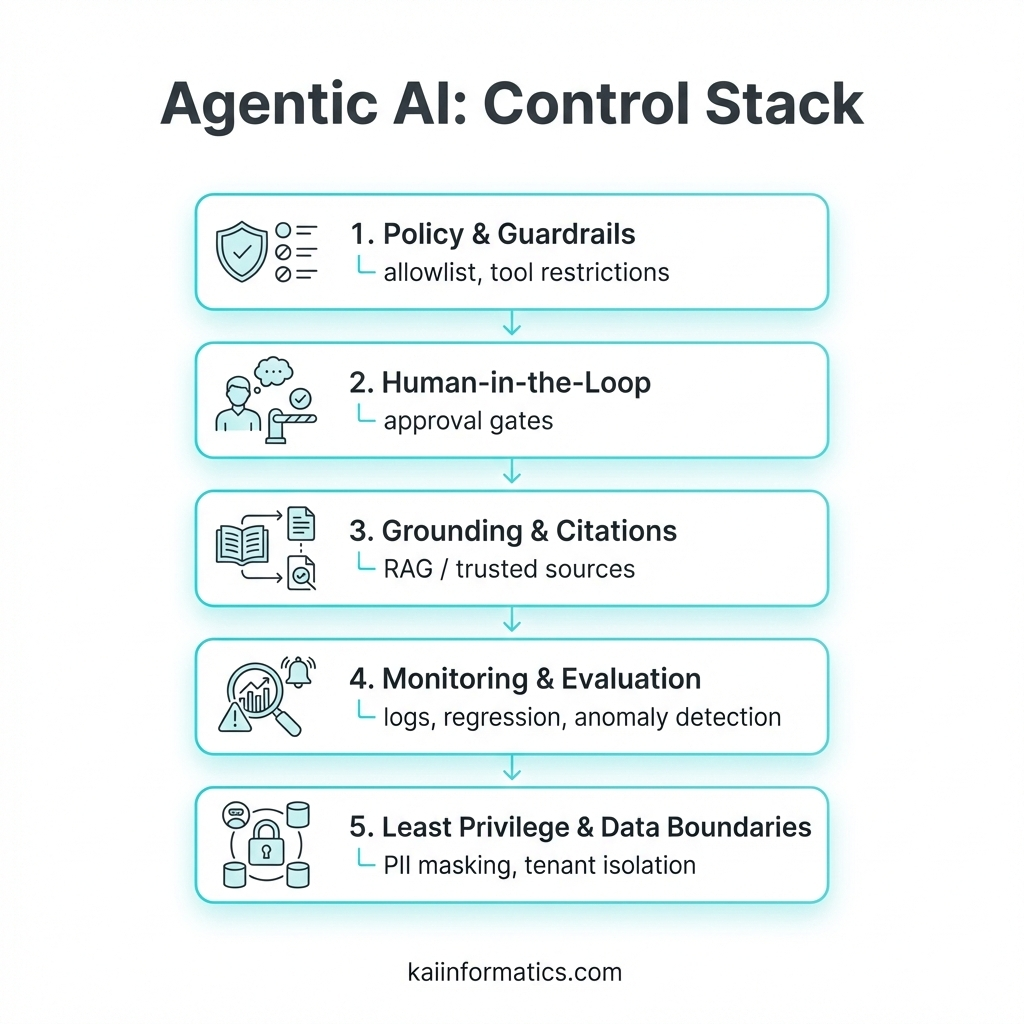
For enterprise customers, the truly critical point begins when these capabilities move into “agentic” (agent-based) use: the model no longer just answers—it can access tools, take steps, and trigger processes. That turns hallucination from “wrong information” into operational risk (wrong transactions, wrong actions, data leakage, compliance violations). This is why in agentic scenarios the goal should be risk reduction and controllability before “better answers.”
In practice, a reliable enterprise setup is built with evidence-based generation plus strict control layers:
- Guardrails and policy enforcement: What tools it can use under which conditions, and what data it must not touch.
- Human-in-the-loop / approval gates: Especially for money, customer data, contracts, and production systems—approval flows instead of “one-click actions.”
- Mandatory sources and traceability: The documents/evidence behind answers, versioning, logs, and an audit trail.
- Evaluation and continuous monitoring: Hallucination rate, tool-call errors, prompt-injection attempts, test sets for failure cases, and regular regression testing.
- Authorization and data boundaries: Least privilege, tenant isolation, PII masking, secure connectors.